Accessing this feature
Your access to the feature described in this article depends on your license package and pricing plan.
To learn which features are available to your organization and how to add more, contact your Hyperscience representative.
Having a diverse and representative Training Set is essential for building a high-quality identification model. The Hyperscience Platform helps you identify which documents are most valuable for training, allowing you to prioritize annotations more efficiently.
How data is curated
The Training Data Curator labels each training document as having high or low importance. The importance is calculated by determining which data would best contribute to the model’s performance. For each group of documents, the system labels the most impactful ones as having high importance.
Before using the Training Data Curator, make sure that you've:
uploaded at least the Recommended Number of Documents. The default minimum value is 100.
Upload a diverse and representative sample of documents to achieve robust model performance.
The goal is to improve the efficiency of the annotation process by requesting an optimal subset that reflects the variety of documents you expect to automate with the model.
Grouping Logic
Documents are grouped based on text and location. Note that new groups will appear every time you run Training Data Analysis. To learn more, see Step 4 of our Training a Semi-structured Model article.
Using the Training Data Curator
Analyze the data.
The Training Data Curator depends on the results from the document grouping. That's why you should first analyze your data.
For more information about data analysis and groups, see Labeling Anomaly Detection.
Before analyzing the data, the importance of each document is N/A.
Reanalyze your data
You should reanalyze your data each time you need to recalculate the importance of your documents, as the system doesn’t re-run the analysis automatically.
After data analysis is finished, the Training Data Health card shows the quality of your training set.

Required documents — the number of additional documents required to start model training. This value is lower than the recommended number of documents, as the system needs fewer examples to initiate the training process than it does to achieve optimal model performance.
Ineligible/Eligible documents — number of documents excluded/included from the training set. For more information, see Document Eligibility Filtering.
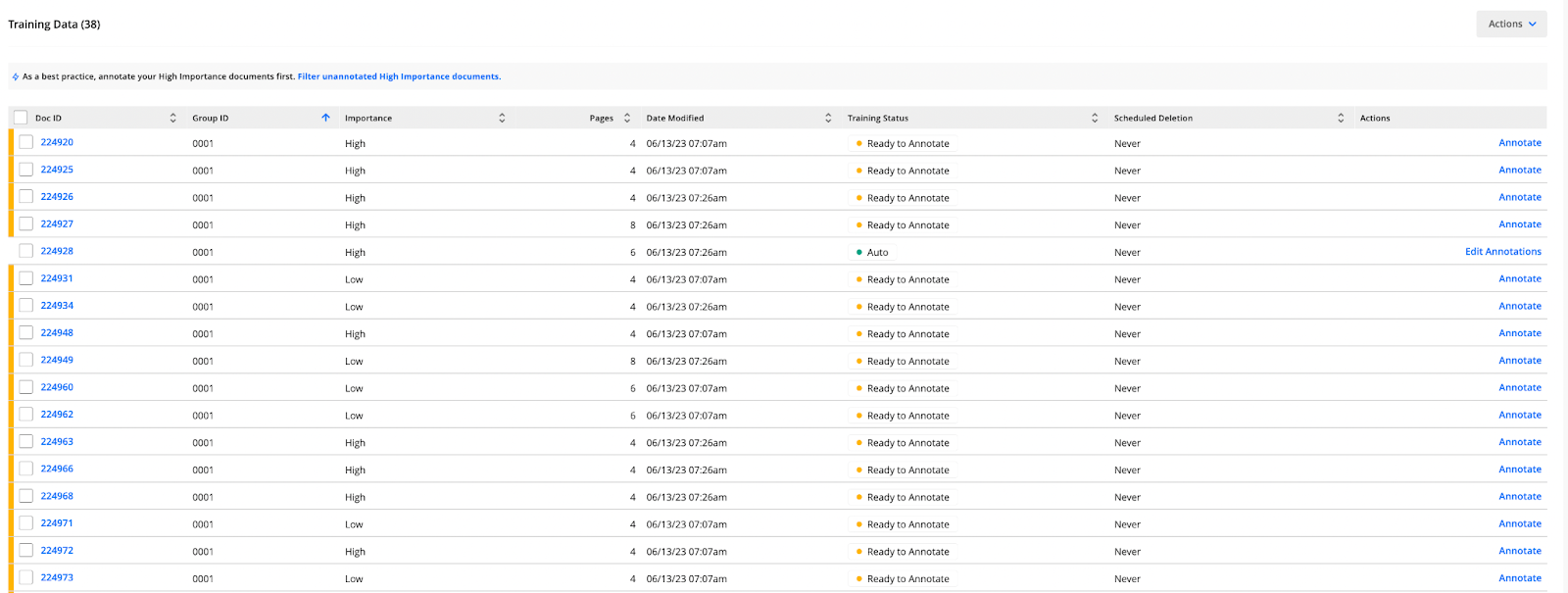
Recommended documents — the recommended number of documents for high-quality model training. The minimum requirement is 100, but achieving a robust model typically requires a larger, more diverse, and representative training set. The importance of each document appears in the Training Data Table. Importance is partially determined by grouping or document similarity - similar documents are grouped and assigned high or low importance, helping you avoid redundant annotations.
High importance — the documents you should annotate first. They are representative of your data and will help you achieve better performance.
Low importance — the documents that are redundant in your training set.
Filter the documents by group
Expand the Filter section and filter the documents by group and by importance.
After you’ve selected a group and importance, Apply Filters.

Annotate the documents with High importance first.
The more representative your training documents are of real-life documents, the better your model will perform with fewer annotations.
We recommend double-checking the ones with Low importance.
The Training Data Curator automatically decides how many documents are of High importance. If the training set has low diversity and high redundancy, you will have a low number of High importance documents, and vice-versa. We recommend uploading more documents, re-analyzing your data, and annotating more High importance documents to improve your model.
All annotated documents will be marked as high importance during training data analysis, while similar ones will be marked as low importance. These updates help keyers annotate documents that are most valuable to the model. If you import documents that have already been annotated, they have high importance by default. То learn more, please contact your Hyperscience representative.
Next steps
Review your training set for inconsistencies to determine whether you need more annotations or corrections. To learn more, see Labeling Anomaly Detection.
As you annotate documents, their importance becomes High, and unannotated documents may be marked as Low importance. Reanalyze your data as you annotate to see the updated information.
Based on the data analysis, the system might determine that a document with a Training Status of Never (excluded from the training) is of High importance. In such cases, we recommend double-checking the document.